Get Started
This article explains how to connect and use a dedicated Amazon Redshift cluster for advanced analytics with Zenoti. This setup provides more flexibility than the standard shared (multi-tenant) Redshift cluster.
Overview
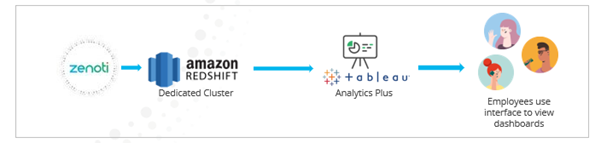
Typically, businesses are hosted on a multi-tenant cluster in Redshift. Due to multiple clients sharing the same environment, there are some restrictions that we impose such as query timeout and the inability to write custom SQLs. If your business would like to bypass these restrictions and achieve a more sophisticated Analytics solution, you can use the Dedicated Redshift offering.
With this offering, Zenoti syncs data into your own dedicated Redshift cluster. You can connect to this cluster and build your own dashboards using Tableau or your own BI tool. You get access to the consolidated data sources as well as the underlying fact and dimension tables. Query timeout limit is extended to 15 mins with this offering and you can write custom SQLs to enable joins between tables. You can also use this offering to pull Zenoti data out of this dedicated cluster into your own data warehouse. This data sync into your own warehouse can be done only once a day during overnight hours.
Note
Data warehousing and BI tool expertise is required to be successful with this offering.
This document helps you get started with connecting to and using your dedicated Redshift cluster.
Prerequisites
You must have Zenoti’s Dedicated Redshift Analytics offering enabled for your business.
Credentials (username, password, JDBC endpoint) will be shared with you by the Zenoti team.
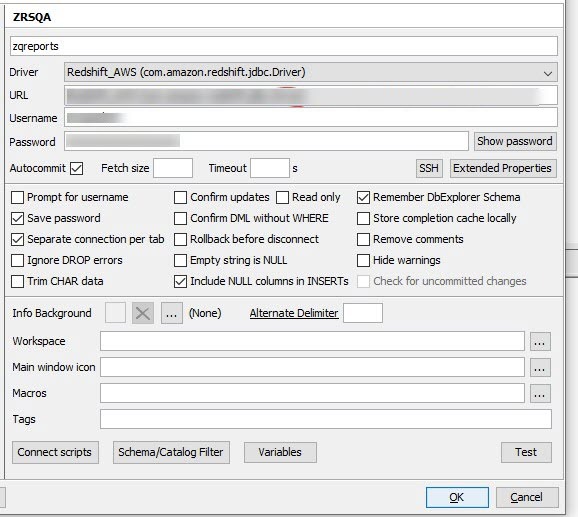
Step 1: Connect to your dedicated Redshift cluster
Install SQL Workbench.
Start SQL Workbench, on the Select Connection Profile dialog box, click Manage Drivers.
In the Manage Drivers dialog box,
From the Driver dropdown list, select the redshift.jdbc driver and give it a name.
In the URL box, enter the JDBC endpoint shared over email.
In the Username box, enter the username shared over email.
In the Password box, enter the password shared over email.
To save the settings, click OK.