Amazon S3 for analytics
Businesses can opt to make their data available through S3 buckets. This data access can be both at the organization level or center/zone level. Businesses can connect to the dedicated S3 bucket and copy data to their local data warehouses.
Business requests for S3 storage to Zenoti's Implementation team.
The implementation team provides credentials to S3 storage to the business.
Zenoti pushes analytics data into S3 buckets.
The entire data is loaded into an S3 bucket (only the first instance). This step is called full load.
After the full load, the data is loaded into S3 in incremental cycles lasting up to 2 hours. Each cycle data is stored in a separate folder. This is called incremental load.
S3 folder has the following structure:
Root directory folder
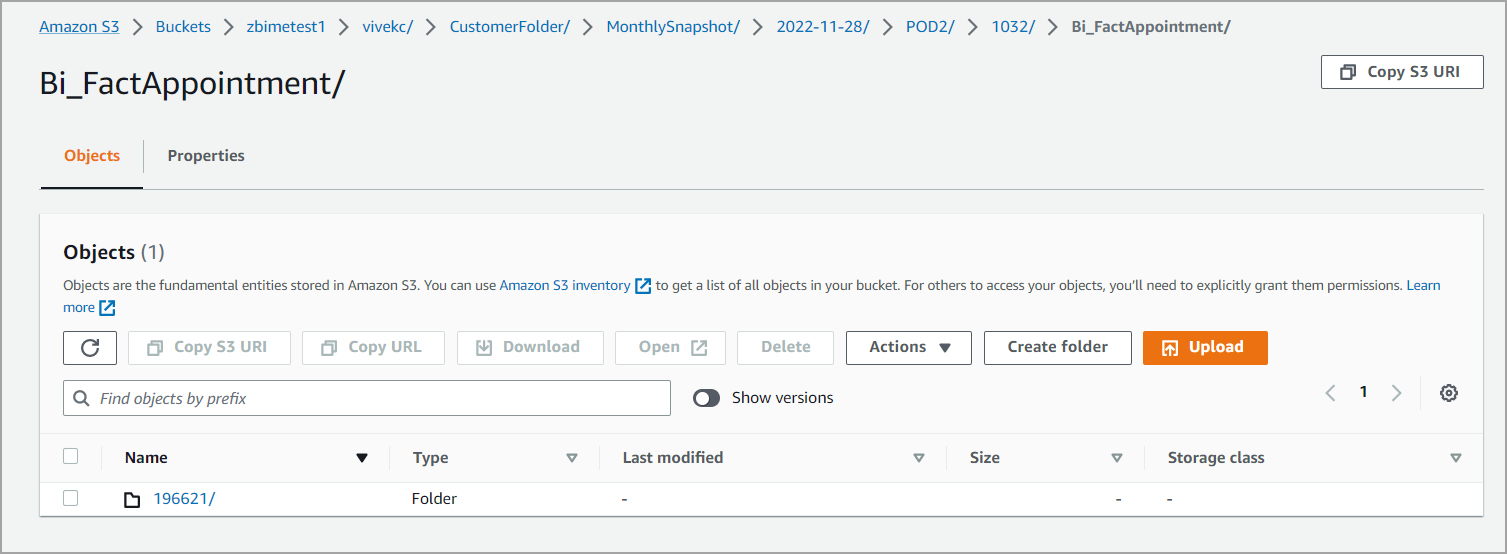
Root directory folder is the topmost folder within which all the other folders reside. In the screenshot below, CustomerFolder is the Root Directory.
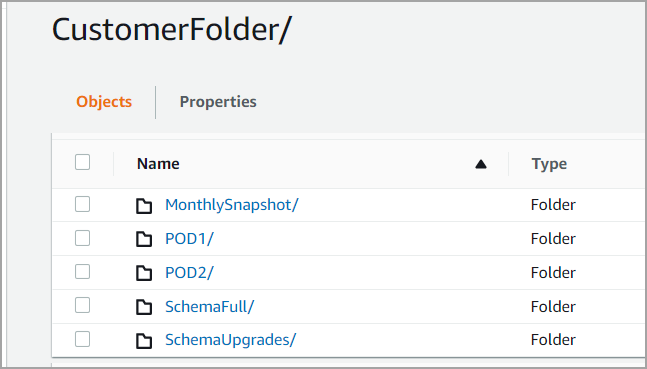
PODName folder
This folder hosts Zenoti's customer data. Usually, businesses see only one PODName (POD1, POD2 in Figure 1) folder. If the business is present across multiple geographies, customer data is stored in multiple PODName folders. GroupID folders reside in PODName folders.
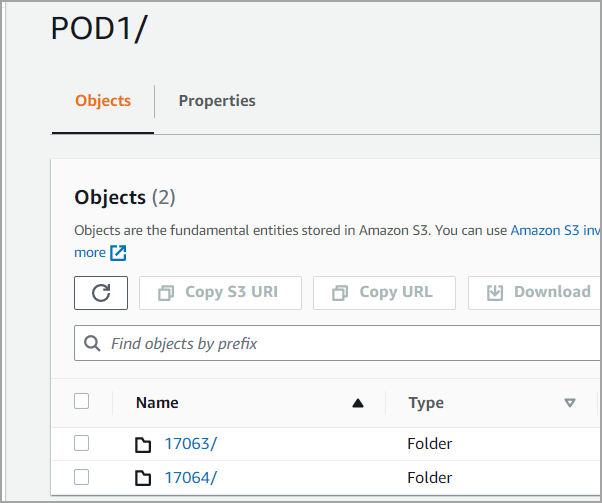
PODName folder has the following structure
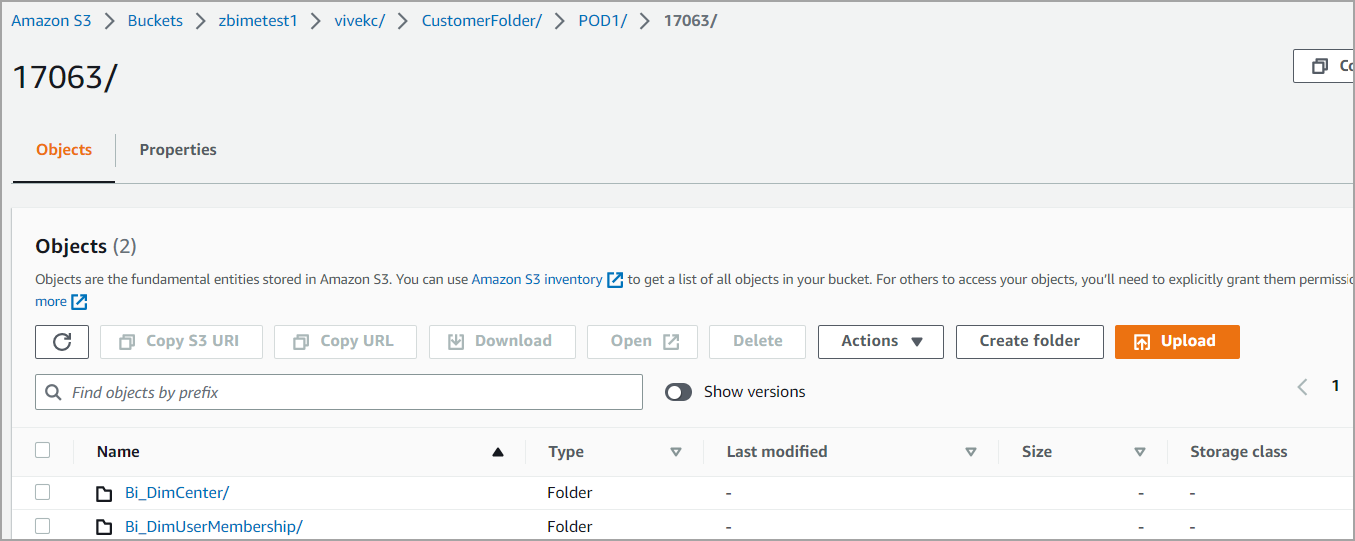
POD:POD1/Groupid/<dim or fact name>/logid/filename.csv
Data loads in S3 buckets incrementally every 1-2 hours. “GroupID” is a serial number indicating the number of incremental cycles of data load.
The smallest value (usually “1”) value indicates full load data and subsequent numbers indicate incremental cycles of data. Each cycle of incremental data load creates a new GroupID folder. When data load is in progress, a temporary folder with the name “<groupid_processing>” is created.
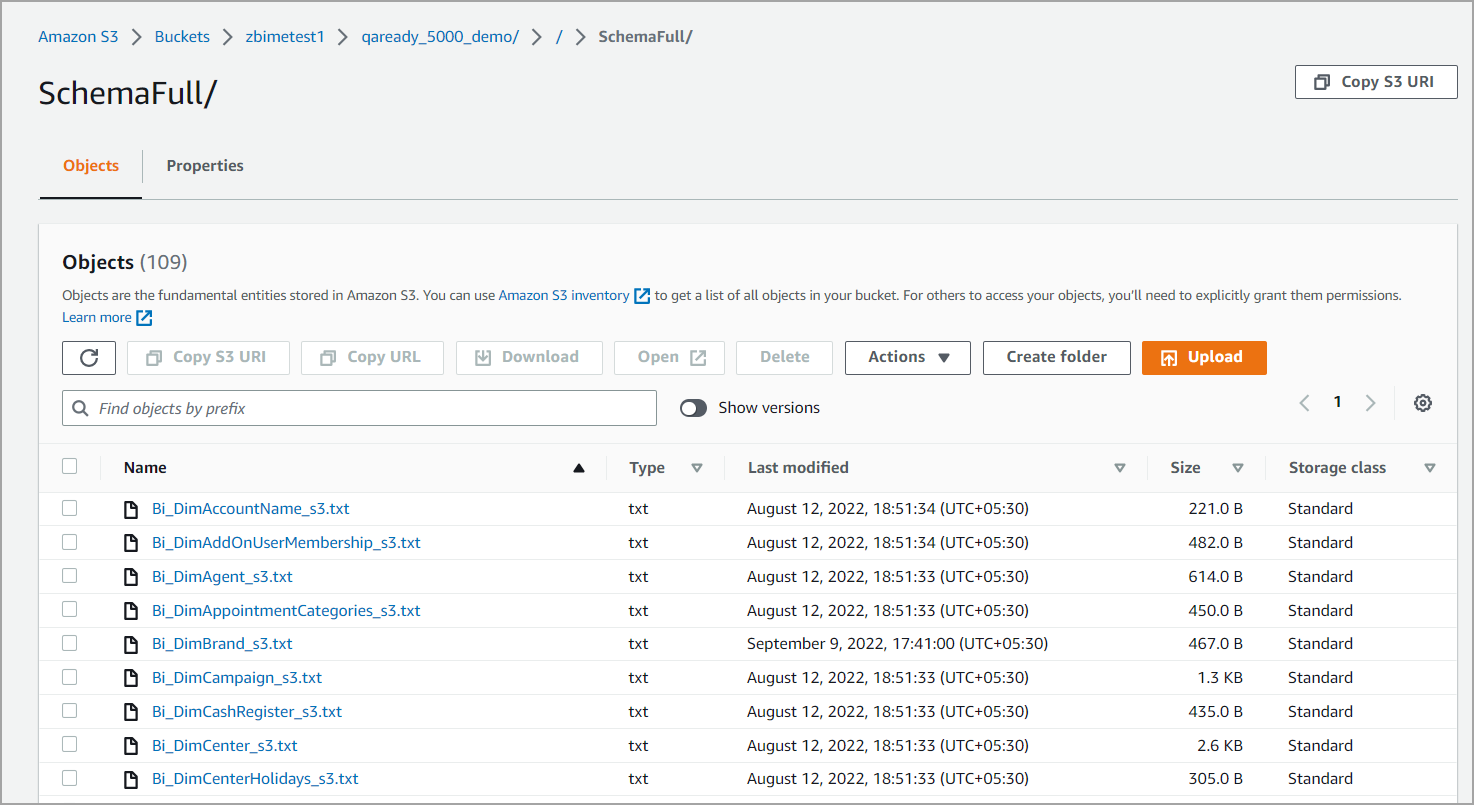
SchemaFull folder
This folder contains the schema of all tables available to the customer. Schema files have .txt format. and the file name is the same as the table name. To copy customer data from S3 to the local system for the first time, run all schema files in this folder first.
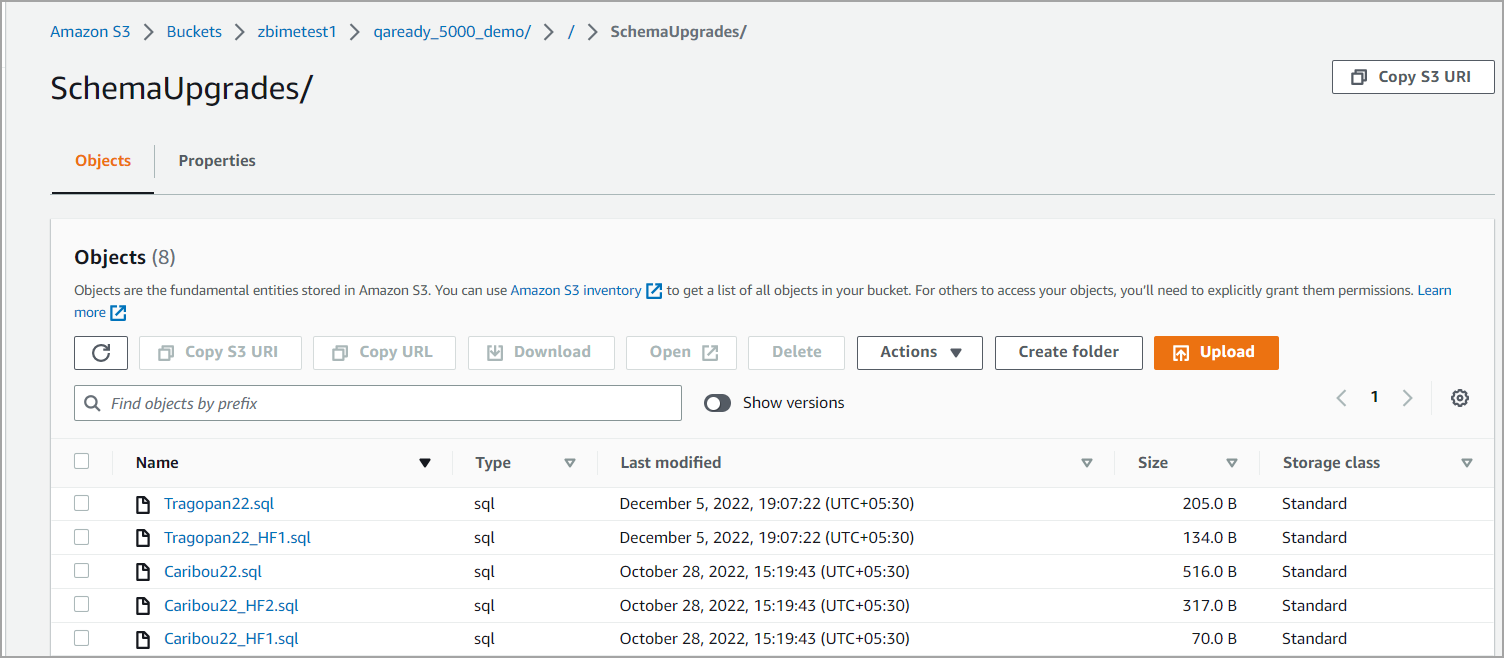
SchemaUpgrade folder
After a customer is onboarded, any change to the schema is updated in this folder (SchemaUpgrade in Figure 1). Whenever there is a new release with schema changes, a new folder is created. Files in this folder are stored in .txt format.
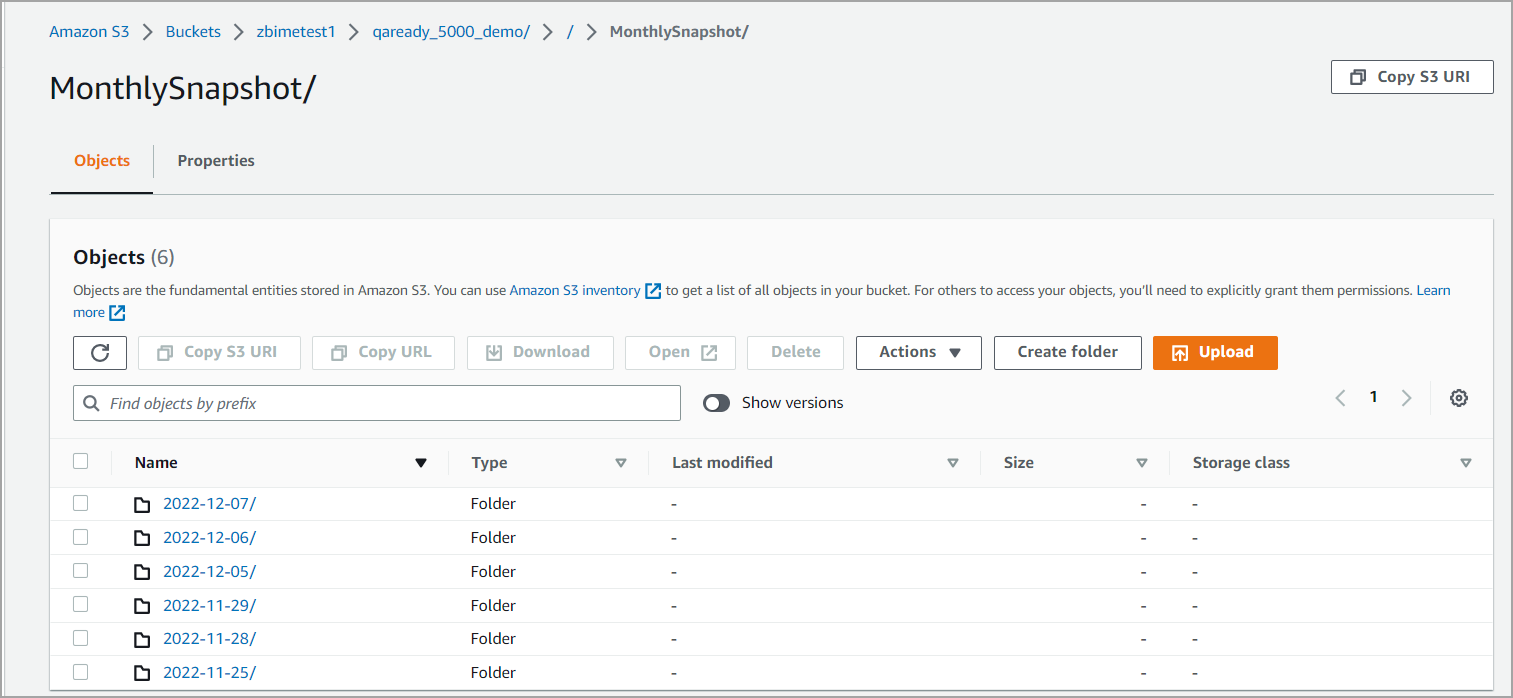
MonthlySnapshot
This folder stores the previous month's data as of the start of the 1st of each month. This helps in situations where the business loses any data of the previous month. Monthly snapshot will be available only after data for all centers are onboarded and historical data is provided. This is to ensure that the historical data doesn't flow into monthly snapshot data.
Note
Monthly snapshot data is stored in csv files. Each fact data is stored in a separate .CSV file and contains data of previous month. The following data tables are excluded from monthly snapshot data.
Bi_FactEmployeeMembershipCommissions
Bi_FactItemCommissionDeductions
Bi_FactMultipleEmployeeCommission
Bi_FactAdoptionSummary
Bi_FactOpportunityCustomFieldValues
Bi_DimUtcToCenterTime
Bi_FactCampaignSummary
Bi_FactEmployeeItemLevelCommissions
MonthlySnapshot folder has the following folder structure:
Customer S3 Bucket/MonthlySnapshot/ExtractDate/PodName/Groupid/FactName/logid.logid.zip
Folder | Description |
|---|---|
ExtractDate | The date on which monthly extract is being taken. |
PODName | Number of folders for each region and its pods. It can have multiple PODName folders depending on how many PODs the customer has onboarded. |
Groupid | Starts with 1000 series and it will be auto incremental for each month’s run. |
FactName | Name of the fact table. Data from each table is stored in a different folder. |
logid | logid is a sequential number for internal refresh tracking. You can ignore it and use the ZIP files present for each fact folder for required month. |
Execute SchemaFull: Execute all scripts in the SchemaFull Folder. This creates all required tables. This is a one time setup.
After the first execution of SchemaFull, execute SchemaUpgrade. This folder is empty when you are setting it for the first time. In the SchemaUpgrade folder, execute any upgrade scripts.
Note
Execute SchemaUpgrade only if there is an upgrade.
Data load fact tables. (Refer to the section below.)
Data load dimension tables. (Refer to the section below)
Difference between fact tables and dimension tables
Fact table | Dimension table |
|---|---|
Contains transactional data | Contains meta data |
Naming convention is bi_fact<dataname> Exception: bi_dimusermembership, which is also a fact table | Naming convention is bi_dim<dataname> Exception: bi_dimusermembership is a fact table. |
Uses delete-insert mechanism Delete-insert mechanism
| Uses update-insert mechanism Update-insert mechanism
|
Sample code to consume CSV files from the Zenoti S3 bucket and synchronize incremental data
The mechanisms for fact tables and dimension tables differ.
The sample code is designed to incrementally load these CSV files into a Redshift database. If you wish to use a different target database system, you will need to implement the same logic using the syntax specific to your chosen database.
Initial Setup Steps:
During the initial setup of the S3 bucket, the Zenoti SRE team will provide you with access credentials for programmatic connection.
If you’re using Redshift as your target, you can directly load data from the S3 bucket. For other database systems, download the CSV files from the S3 bucket using the provided credentials.
The S3 bucket contains a ‘SchemaFull’ folder, which provides a complete schema for all dimension and fact tables. These schema files are compatible with Redshift.
After creating target tables using these schema files, you can begin consuming data from the S3 bucket.
Ignore the ‘SchemaUpgrade’ folder during initial setup. Refer to this folder for upgrades after the initial setup is complete. Any future upgrades must be consumed before new CSV files.
Incremental Data Consumption for Fact Table from S3:
To consume data from S3, process ETL groups incrementally. Each group contains individual fact folders with CSV files of incremental data.
Zenoti facts are built with a delete-insert mechanism. Any updates or deletions are indicated by void=1. This means that all primary key records with void=1 in the CSV file have been updated or deleted and should be removed from the target. All other records with void=0 should be inserted.
To implement this logic, create a stage table to load data from the CSV file. Use the same schema file of the fact table with _stage appended to the table name.
Use AWS credentials and S3 file paths to load data from the CSV file into the stage table.
Once the stage table is ready, delete records from the target table that match those in the stage table based on primary key, organization ID, and void=1 in the stage table.
After deleting records based on primary key and void=1 from target table, insert all records from stage table into target table.
Sample code
-- Create stage table to load the data from csv : create temporary table Bi_FactForms_stage ( FormId VARCHAR(36) ,factformid DECIMAL(19,0) ,GuestId VARCHAR(36) ,TherapistId VARCHAR(36) ,ReviewedBy VARCHAR(36) ,AppointmentId VARCHAR(36) ,CenterId VARCHAR(36) ,Serviceid VARCHAR(36) ,ReviewedOn TIMESTAMP ,Submitteddate TIMESTAMP ,Startdate TIMESTAMP ,Isformsubmitted INT ,Formtype INT ,Formsource VARCHAR(64) ,Fieldname VARCHAR(65535) ,Value1 FLOAT ,Value2 TIMESTAMP ,Value3 BOOLEAN ,Value4 VARCHAR(65535) ,DataTypeDesc VARCHAR(144) ,Pointer INT ,FormVoided BOOLEAN ,void BOOLEAN ,ReviewNeeded BOOLEAN ,FormAppointmentStatus INT ,AppointmentNoShowOrCancel INT ,isappointmentvoided BOOLEAN ,formexpirydate TIMESTAMP ,LastUpdatedDate TIMESTAMP ,ETLCreatedDate TIMESTAMP ,PodName VARCHAR(20) ,OrganizationId VARCHAR(36) ,IsV3Form BOOLEAN ) distkey(factformid) sortkey(factformid) ; ---- COPY data from S3 csv file into a stage table copy Bi_FactForms_stage from '<S3 csv file path>' credentials 'aws_access_key_id=<aWS Access key>;aws_secret_access_key=<AWS secret key>' COMPUPDATE OFF region '<AWS Region>' csv -- Above copy command will load the data into stage table. -- Delete the pk which are matching with stage table and have void=1 DELETE FROM Bi_FactForms_s3 USING Bi_FactForms_stage stage WHERE Bi_FactForms_s3.factformid = stage.factformid AND Bi_FactForms_s3.organizationid=stage.organizationid AND stage.void = 1; -- Load data from stage table to fact table where void=0 INSERT INTO Bi_FactForms_s3 ( FormId ,factformid ,GuestId ,TherapistId ,ReviewedBy ,AppointmentId ,CenterId ,Serviceid ,ReviewedOn ,Submitteddate ,Startdate ,Isformsubmitted ,Formtype ,Formsource ,Fieldname ,Value1 ,Value2 ,Value3 ,Value4 ,DataTypeDesc ,Pointer ,FormVoided ,void ,ReviewNeeded ,FormAppointmentStatus ,AppointmentNoShowOrCancel ,isappointmentvoided ,formexpirydate ,LastUpdatedDate ,ETLCreatedDate ,PodName ,OrganizationId ,IsV3Form ) SELECT FormId ,factformid ,GuestId ,TherapistId ,ReviewedBy ,AppointmentId ,CenterId ,Serviceid ,ReviewedOn ,Submitteddate ,Startdate ,Isformsubmitted ,Formtype ,Formsource ,Fieldname ,Value1 ,Value2 ,Value3 ,Value4 ,DataTypeDesc ,Pointer ,FormVoided ,void ,ReviewNeeded ,FormAppointmentStatus ,AppointmentNoShowOrCancel ,isappointmentvoided ,formexpirydate ,LastUpdatedDate ,ETLCreatedDate ,PodName ,OrganizationId ,IsV3Form FROM Bi_FactForms_stage stage WHERE stage.void = 0;
Incremental Data Consumption for Dimension Table from S3:
To consume data from S3, process ETL groups incrementally. Each group contains individual dimension folders with CSV files of incremental data.
Zenoti dimensions are built with an update-insert mechanism so any record present in the CSV file with matching primary key needs to be updated in the target table and new records should be inserted in the target table.
To implement this logic, create a stage table to load data from the CSV file. Use the same schema file of fact table with _stage appended to the table name.
Use AWS credentials and S3 file paths to load data from the CSV file into stage table.
Once stage table is ready, update target table records for which we have matching entry in stage table based on primary key.
After updating target table for matching records, delete such records from stage table and insert all remaining records from the stage table into target table (new inserts).
-- Create stage table to load the data from csv : create temporary table Bi_DimUser_stage ( userid NVARCHAR(144) ,firstname NVARCHAR(160) ,lastname NVARCHAR(256) ,middlename NVARCHAR(128) ,address1 NVARCHAR(2048) ,address2 NVARCHAR(2048) ,city NVARCHAR(128) ,StateOther NVARCHAR(128) ,ZipCode NVARCHAR(128) ,UserTypeID VARCHAR(36) ,UserTypeName NVARCHAR(128) ,CreationDt TIMESTAMP ,CenterID VARCHAR(36) ,Email NVARCHAR(256) ,homephone NVARCHAR(64) ,mobilephone NVARCHAR(64) ,workphone NVARCHAR(64) ,username NVARCHAR(256) ,usercode NVARCHAR(512) ,lastlogin TIMESTAMP ,gender INT ,dob TIMESTAMP ,preferredTherapist VARCHAR(36) ,preferredRoom VARCHAR(36) ,otherpreferences NVARCHAR(65535) ,referralsourceid VARCHAR(36) ,roomno NVARCHAR(80) ,referredby VARCHAR(36) ,anniversarydate TIMESTAMP ,PreferedCenerId VARCHAR(36) ,registrationsource INT ,customerapplogin INT ,mobilecountrydname NVARCHAR(4096) ,mobilecountrysname NVARCHAR(4096) ,stateDispName NVARCHAR(4096) ,stateShortName NVARCHAR(4096) ,statecode NVARCHAR(40) ,CountryDName NVARCHAR(4096) ,CountrySName NVARCHAR(4096) ,ReceiveTransactionalSMS BOOLEAN ,ReceiveMarketingSMS BOOLEAN ,UserPK DECIMAL(19,0) ,UnSubscribeToTransactionalEmail BOOLEAN ,UnSubscribeToMarketingEmail BOOLEAN ,PasswordUpdatedOn TIMESTAMP ,ReceiveTransactionalEMail BOOLEAN ,ReceiveMarketingEMail BOOLEAN ,AcceptedTAndC INT ,NationalityFK INT ,DOB_IncompleteYear NVARCHAR(20) ,organizationid VARCHAR(36) ,Void BOOLEAN ,employeetags VARCHAR(MAX) ,usertags VARCHAR(MAX) ,JobName NVARCHAR(1020) ,JobCode NVARCHAR(8000) ,GuestReferralSource NVARCHAR(1600) ,EmailState INT ,MandatoryBreakTimePerDay INT ,PhoneCode INT ,StartDate TIMESTAMP ,LastDate TIMESTAMP ,NoSaleComments VARCHAR(MAX) ,AdditionalField1 NVARCHAR(4096) ,AdditionalField2 NVARCHAR(4096) ,EmployeeCode NVARCHAR(512) ,RelationshipManager VARCHAR(36) ,EtlLastUpdatedOn TIMESTAMP ,EtlLastUpdatedBy NVARCHAR(512) ,Date1 TIMESTAMP ,Date2 TIMESTAMP ,PodName VARCHAR(20) ,CTEtlLastUpdatedOn TIMESTAMP ) distkey(centerid) sortkey(userid) ; -- COPY data from S3 csv file into a stage table copy Bi_DimUser_stage from '<S3 csv file path>' credentials 'aws_access_key_id=<aWS Access key>;aws_secret_access_key=<AWS secret key>' COMPUPDATE OFF region '<AWS Region>' csv --Update target table for matching records: update Bi_DimUser_s3 set userid =stage.userid ,firstname =stage.firstname ,lastname =stage.lastname ,middlename =stage.middlename ,address1 =stage.address1 ,address2 =stage.address2 ,city =stage.city ,StateOther =stage.StateOther ,ZipCode =stage.ZipCode ,UserTypeID =stage.UserTypeID ,UserTypeName =stage.UserTypeName ,CreationDt =stage.CreationDt ,CenterID =stage.CenterID ,Email =stage.Email ,homephone =stage.homephone ,mobilephone =stage.mobilephone ,workphone =stage.workphone ,username =stage.username ,usercode =stage.usercode ,lastlogin =stage.lastlogin ,gender =stage.gender ,dob =stage.dob ,preferredTherapist =stage.preferredTherapist ,preferredRoom =stage.preferredRoom ,otherpreferences =stage.otherpreferences ,referralsourceid =stage.referralsourceid ,roomno =stage.roomno ,referredby =stage.referredby ,anniversarydate =stage.anniversarydate ,PreferedCenerId =stage.PreferedCenerId ,registrationsource =stage.registrationsource ,customerapplogin =stage.customerapplogin ,mobilecountrydname =stage.mobilecountrydname ,mobilecountrysname =stage.mobilecountrysname ,stateDispName =stage.stateDispName ,stateShortName =stage.stateShortName ,statecode =stage.statecode ,CountryDName =stage.CountryDName ,CountrySName =stage.CountrySName ,ReceiveTransactionalSMS =stage.ReceiveTransactionalSMS ,ReceiveMarketingSMS =stage.ReceiveMarketingSMS ,UserPK =stage.UserPK ,UnSubscribeToTransactionalEmail =stage.UnSubscribeToTransactionalEmail ,UnSubscribeToMarketingEmail =stage.UnSubscribeToMarketingEmail ,PasswordUpdatedOn =stage.PasswordUpdatedOn ,ReceiveTransactionalEMail =stage.ReceiveTransactionalEMail ,ReceiveMarketingEMail =stage.ReceiveMarketingEMail ,AcceptedTAndC =stage.AcceptedTAndC ,NationalityFK =stage.NationalityFK ,DOB_IncompleteYear =stage.DOB_IncompleteYear ,organizationid =stage.organizationid ,Void =stage.Void ,employeetags =stage.employeetags ,usertags =stage.usertags ,JobName =stage.JobName ,JobCode =stage.JobCode ,GuestReferralSource =stage.GuestReferralSource ,EmailState =stage.EmailState ,MandatoryBreakTimePerDay =stage.MandatoryBreakTimePerDay ,PhoneCode =stage.PhoneCode ,StartDate =stage.StartDate ,LastDate =stage.LastDate ,NoSaleComments =stage.NoSaleComments ,AdditionalField1 =stage.AdditionalField1 ,AdditionalField2 =stage.AdditionalField2 ,EmployeeCode =stage.EmployeeCode ,RelationshipManager =stage.RelationshipManager ,EtlLastUpdatedOn =stage.EtlLastUpdatedOn ,EtlLastUpdatedBy =stage.EtlLastUpdatedBy ,Date1 =stage.Date1 ,Date2 =stage.Date2 ,PodName =stage.PodName ,CTEtlLastUpdatedOn =stage.CTEtlLastUpdatedOn from Bi_DimUser_stage stage where stage.userid = Bi_DimUser_s3.userid; -- Delete the records from stage which are matching with the target delete from Bi_DimUser_stage using Bi_DimUser_s3 target where Bi_DimUser_stage.userid = target.userid; -- insert new records present in the stage to target( new incremental inserts to the dim) INSERT INTO Bi_DimUser_s3 ( userid ,firstname ,lastname ,middlename ,address1 ,address2 ,city ,StateOther ,ZipCode ,UserTypeID ,UserTypeName ,CreationDt ,CenterID ,Email ,homephone ,mobilephone ,workphone ,username ,usercode ,lastlogin ,gender ,dob ,preferredTherapist ,preferredRoom ,otherpreferences ,referralsourceid ,roomno ,referredby ,anniversarydate ,PreferedCenerId ,registrationsource ,customerapplogin ,mobilecountrydname ,mobilecountrysname ,stateDispName ,stateShortName ,statecode ,CountryDName ,CountrySName ,ReceiveTransactionalSMS ,ReceiveMarketingSMS ,UserPK ,UnSubscribeToTransactionalEmail ,UnSubscribeToMarketingEmail ,PasswordUpdatedOn ,ReceiveTransactionalEMail ,ReceiveMarketingEMail ,AcceptedTAndC ,NationalityFK ,DOB_IncompleteYear ,organizationid ,Void ,employeetags ,usertags ,JobName ,JobCode ,GuestReferralSource ,EmailState ,MandatoryBreakTimePerDay ,PhoneCode ,StartDate ,LastDate ,NoSaleComments ,AdditionalField1 ,AdditionalField2 ,EmployeeCode ,RelationshipManager ,EtlLastUpdatedOn ,EtlLastUpdatedBy ,Date1 ,Date2 ,PodName ,CTEtlLastUpdatedOn ) select userid ,firstname ,lastname ,middlename ,address1 ,address2 ,city ,StateOther ,ZipCode ,UserTypeID ,UserTypeName ,CreationDt ,CenterID ,Email ,homephone ,mobilephone ,workphone ,username ,usercode ,lastlogin ,gender ,dob ,preferredTherapist ,preferredRoom ,otherpreferences ,referralsourceid ,roomno ,referredby ,anniversarydate ,PreferedCenerId ,registrationsource ,customerapplogin ,mobilecountrydname ,mobilecountrysname ,stateDispName ,stateShortName ,statecode ,CountryDName ,CountrySName ,ReceiveTransactionalSMS ,ReceiveMarketingSMS ,UserPK ,UnSubscribeToTransactionalEmail ,UnSubscribeToMarketingEmail ,PasswordUpdatedOn ,ReceiveTransactionalEMail ,ReceiveMarketingEMail ,AcceptedTAndC ,NationalityFK ,DOB_IncompleteYear ,organizationid ,Void ,employeetags ,usertags ,JobName ,JobCode ,GuestReferralSource ,EmailState ,MandatoryBreakTimePerDay ,PhoneCode ,StartDate ,LastDate ,NoSaleComments ,AdditionalField1 ,AdditionalField2 ,EmployeeCode ,RelationshipManager ,EtlLastUpdatedOn ,EtlLastUpdatedBy ,Date1 ,Date2 ,PodName ,CTEtlLastUpdatedOn from Bi_DimUser_stage stage;
Data for center/zone access
For each center/zone subscription, an individual S3 bucket is created and that bucket has data related to that center/zone.
As centers / zones are coupled with organization, some settings at the organization apply to centers as well. In such cases, data will be common across all s3 buckets for center/zone within the organization. Below is the list of tables where organization-level data is provided.
Fact tables
bi_factfeedbackv2
bi_factitemcommissiondeductions
Dimension tables
bi_dimagent
bi_dimappointmentcategories
bi_dimcampaign
bi_dimcategoryproducts
bi_dimcategoryservices
bi_dimcustomforms
bi_dimdiscount
bi_dimdonations
bi_dimemployeebreakcategories
bi_dimemployeeschedulestatus
bi_dimfactchanges
bi_dimgiftcard
bi_dimissuecategories
bi_dimissuesource
bi_dimissuesubcategories
bi_dimissuetreatment
bi_dimitems
bi_dimloyaltypointprograms
While building data pipeline to extract data from .CSV files, always use the column names in the SELECT query and never use SELECT *. This will help in keeping extract program independent of schema changes on Zenoti side.
It is advised to consume any new schema changes first and then start consuming incremental data.
The business should have a logging mechanism to keep track of the last execution and what the last <GroupID> consumed was.
While extracting data from S3, use intermediate/staging table to get the data from the .CSV files and then based on the logic given for consuming incremental data from the .CSV file, merge it with the target tables in the warehouse.
Before every data sync cycle, look for changes in SchemaFull and SchemaUpgrade folders based on timestamp. If there are any new files or update on existing schema files, execute these folders before continuing with data sync.