Get Started
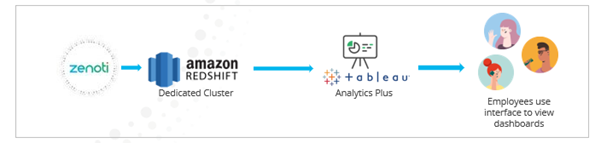
Dedicated Redshift cluster for analytics
Typically, businesses are hosted on a multi-tenant cluster in Redshift. Due to multiple clients sharing the same environment, there are some restrictions that we impose such as query timeout and the inability to write custom SQLs. If your business would like to bypass these restrictions and achieve a more sophisticated Analytics solution, you can use the Dedicated Redshift offering.
With this offering, Zenoti syncs data into your own dedicated Redshift cluster. You can connect to this cluster and build your own dashboards using Tableau or your own BI tool. You get access to the consolidated data sources as well as the underlying fact and dimension tables. Query timeout limit is extended to 15 mins with this offering and you can write custom SQLs to enable joins between tables. You can also use this offering to pull Zenoti data out of this dedicated cluster into your own data warehouse. This data sync into your own warehouse can be done only once a day during overnight hours.
Note
Data warehousing and BI tool expertise is required to be successful with this offering.
This document helps you get started with connecting to and using your dedicated Redshift cluster.
Connect to a dedicated Redshift cluster
Install SQL Workbench.
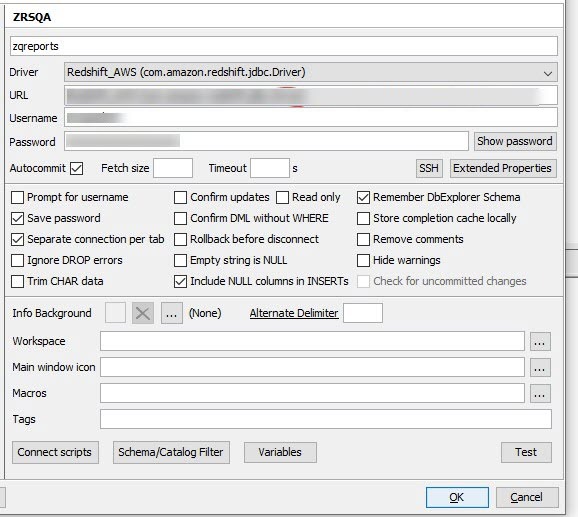
Start SQL Workbench, on the Select Connection Profile dialog box, click Manage Drivers.
In the Manage Drivers dialog box,
From the Driver dropdown list, select the redshift.jdbc driver and give it a name.
In the URL box, enter the JDBC endpoint shared over email.
In the Username box, enter the username shared over email.
In the Password box, enter the password shared over email.
To save the settings, click OK.
Move data from a dedicated Redshift cluster into another data warehouse
Incremental sync from the dedicated Redshift cluster into another warehouse can be accomplished by making use of the fact and dimension tables. It cannot be done directly from the consolidated data sources. If consolidated data sources are required in the warehouse, the business can perform incremental sync using the fact and dimension tables and then use the SQLs to generate the consolidated data sources from the facts & dimensions. This incremental sync can be done once a day during overnight hours. It cannot be done multiple times a day.
The following are the steps to perform incremental sync of the fact and dimension tables:
Do a one-time full load sync of the data.
From then onwards, note down the time stamp that the last sync was initiated and use that for the next incremental cycle.
Before pulling incremental load, the records that have been reprocessed since the last sync have to be deleted. To do this:
Identify all the PKs that got updated in the Bi_DimFactChanges table since the time the last sync was done. Use the etlcreated timestamp to identify the updates.
Identify all the PKs that got updated in the fact and dimension tables in the dedicated Redshift since the time the last sync was done. Use the etlcreated timestamp in each table to identify the updates.
Compile all the distinct PKs from steps a and b and delete these records from the tables in your warehouse.
Next, pull in the incremental load by identifying all the PKs that got updated in the fact and dimension tables in the dedicated Redshift since the time the last sync was done. Use the etlcreated timestamp in each table to identify the updates. Append these records to the tables in your warehouse.
Note
Records are never deleted from dimension tables, they are only updated.
Maintain a log of the timestamps (in UTC) when each sync is initiated to help identify the delta load for the next sync.
Use this table to see how to join each fact to the Bi_DimFactChanges table.
Fact Table | Column from Fact to be joined with Bi_DimFactChanges (factpk) |
Bi_FactEmployeeCommission | FactEmployeeCommissionId |
Bi_FactEmployeeSalary | FactEmployeeSalaryId |
Bi_FactEmployeeSchedule | FactEmployeeScheduleId |
Bi_FactEmployeePay | FactEmployeePayId |
Bi_FactIssues | IssuePK |
Bi_FactInvoiceItem | factinvoiceitemid |
Bi_FactCollections | factcollectionid |
Bi_FactAppointment | factAppointmentid |
Bi_FactTurnAways | factsegmentid |
Bi_FactOpportunityCustomFieldValues | opportunityfieldvalueid |
Bi_FactScheduledCollections | factsegmentid |
Bi_FactPackageUserRedemptions | factsegmentid |
Bi_FactDeletedAppointment | factsegmentid |
Bi_FactEmployeeTipsAndSSGDetails | factsegmentid |
Bi_FactMultipleEmployeeCommission | empcommissionpk |
Bi_FactCampaignSummary | FactCampaignId |
Bi_FactMembershipUserRedemptions | factsegmentid |
Bi_FactPettyCashDetails | FactSegmentID |
Bi_FactCashRegister | factcashregisterid |
Bi_FactItemCommissionDeductions | deductionpk |
Bi_FactEmployeeItemLevelCommissions | employeeitemid |
Bi_FactEmployeeMembershipCommissions | empmembershippk |
Bi_FactFeedBackV2 | FeedBackId |
Bi_FactLoyaltyPoints | LoyaltyPointsId |
Bi_FactGuestTierChanges | GuestTierChangesId |
Bi_FactGuestMergeLog | GuestMergeHistoryPK |
Bi_FactGiftCards | factgiftcardid |
Bi_FactCampaignDiscount | factcampaigndiscountid |
Bi_FactEmpSalary | FactEmployeeSalaryId |
Bi_FactEmployeeInvoiceItemRevenue | FactEmployeeInvoiceItemRevenueID |
Bi_DimUserMembership | DimUserMembershipId |
Bi_factmembershiptransfers | FactMembershipTransferId |
Bi_factguestcheckin | Factguestcheckinid |
Bi_factmembershipdunning | FactMembershipDunningId |
Bi_factuserguestpass | Factuserguestpassid |
Bi_factinventory | Factinventorypk |
Redshift FAQs
Detail out cluster capacity, performance, and concurrency expectations
When users run queries in Amazon Redshift, the queries are routed to query queues. Each query queue contains several query slots. Each queue is allocated a portion of the cluster's available memory. A queue's memory is divided among the queue's query slots.
We use Amazon Redshift Dense Compute (DC2) nodes. Each node comes with 160 GB of storage.
What is the ETL strategy? Is it a full or incremental load?
In Analytics, when we set up a customer for the first time, we do a full sync and copy over all the masters and transactional data from the CORE database to date. We support the current year minus three years of data. After completing the full sync, the ETL picks up changes from the last successful sync and processes them in the current cycle.
How does it handle upserts, deletes, lost data recovery, etc.?
We don't maintain versions in Redshift, we always delete and insert changes. Hard deletes are possible.
What is stored in fact tables vs. dimension tables?
We store material values in fact tables and master attributes in dimensions. Each fact table is linked to dimensions by using WIDs. WID is the PK in the master table (Parent-Child relationship is established).
What is the data growth or purging strategy? What is the current capacity and how can we scale?
As of today, there is no purging strategy. It will change going forward and we will start maintaining only the current year minus three years data in Redshift.
We will scale whenever the cluster capacity reaches 60% or the query performance degrades.
What are the sync cycles? Are they on-demand syncs or regular syncs?
There is no on-demand sync. The ETL is deployed as a service scheduled to run continuously except for a daily three-hour maintenance window. The maintenance window is scheduled during non-production hours. In the maintenance window- we write CT's afresh every time and this needs the data to be sorted or distributed and vacuumed for better query performance.
Once we start writing our CT's incrementally, the need for a maintenance window will go away. Whenever additional data needs to be synced for an existing customer, we use batch mechanism, which ensures that the refresh is not delayed and that additional data gets synced in increments.
Do we allow any writes beyond Zenoti data into the cluster?
We don't support this.